
Why the end of the speed-versus-brains trade-off changes everything for ISV economics.
I saw the benchmark data for Gemini 3.5 Flash today. Honestly, it completely breaks the mental model I use to evaluate these systems.
When I talk to enterprise teams, they usually have to pick their poison. Do you want the system to be brilliant? Okay, then your users get to stare at a loading spinner. Do you want the response to be instant? Great, but the output might be shallow. That is just how the industry worked. You traded brains for speed.
Gemini 3.5 Flash takes that trade-off and tosses it out the window. It brings heavy-duty reasoning to the table but runs like a lightweight model. For ISVs building the next generation of applications, this is the exact shift we’ve been waiting for.
Breaking The Intelligence Speed Barrier
That classic AI curve always forces your hand. You build a complex agentic loop, and suddenly your application feels like it is crawling. Gemini 3.5 Flash refuses to play that game. It hits the exact same intelligence tier as massive models like Claude Opus 4.7. The difference is it churns out tokens almost four times faster! We aren’t talking about a small bump here. It’s a complete rethink of what you can build for real-time users. Consider the following chart from Artificial Analysis:
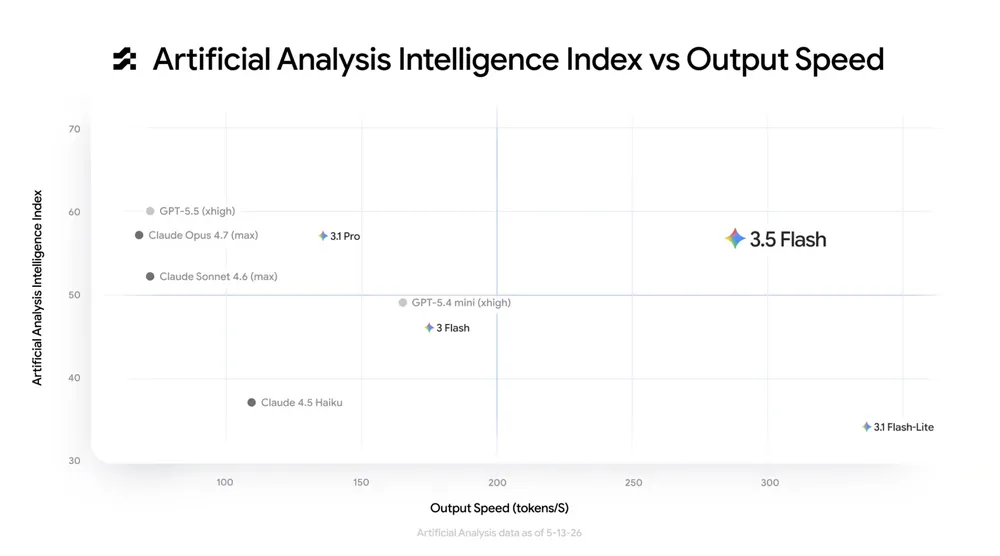
Gemini 3.5 Flash blazes along at roughly 290 tokens per second. Meanwhile, it holds down an intelligence index right around 56. That puts its brain squarely in the same category as Claude Opus 4.7 and Gemini 3.1 Pro, but the generation speed is entirely different. Sure, GPT-5.5 edges it out slightly in raw smarts, but it crawls at 80 tokens per second!
When you sit down to architect a new feature, that speed differential changes everything. A task that takes GPT-5.5 ten seconds to complete will finish in under three seconds with Gemini 3.5 Flash. That’s the difference between a user abandoning a workflow and a user feeling like they have a true assistant. It’s three reasoning loops in the time it takes to do one!
Performance Benchmarks And Enterprise Implications
The underlying metrics here are completely wild. It grabbed an 83.6% on the MCP Atlas agentic benchmark. That beats both Claude Opus 4.7 and GPT-5.5 when you look at pure agentic tasks. It also dominated the Toolathlon benchmark, hitting 56.5%. Add a 1 million token context window into the mix, and the possibilities open up incredibly fast.
So why does this matter for ISVs? Because latency kills products dead. People hate waiting for a response. They tolerate it for now because the novelty of AI is still fresh, but that grace period is ending. Enterprise buyers expect their tools to be snappy.
With Gemini 3.5 Flash, your platform suddenly runs complex agentic reasoning in a snap. We’re talking about voice assistants that don’t pause awkwardly, and coding copilots that actually keep up with your typing. Imagine a customer support agent that can read through a massive thread, query a database, and draft a personalized reply in two seconds. This is the new baseline.
Aggressive Pricing For Scale
Speed isn’t the only angle Google is playing. They’re making a massive move on price. Gemini 3.5 Flash hits the market at $1.50 per million input tokens. Output tokens sit at $9.00 per million on the standard tier. If your architecture leans heavily on context caching, that input token cost plummets to an almost ridiculous $0.15 per million.
That context caching feature is the secret weapon for ISVs. If you have a massive knowledge base or a complex system prompt that every user queries against, you cache it once. Every subsequent query against that cached data costs pennies on the dollar.
That kind of pricing flips the economics of enterprise deployments upside down. You don’t have to bankrupt your engineering team to run deep agentic loops anymore. Google reckons that shifting big workloads over to this model will save companies massive chunks of cash. For ISVs, that savings translates to real margin recovery and ultimately, higher valuations. You get to ship smarter features without eroding margin or jacking up prices.
The Future Is Fast And Smart
Think about how much time we’ve spent building weird routing hacks. We constantly try to send easy questions to fast models. Then we send the hard questions to the slow ones. We build complex orchestration layers just to manage the latency budget. Gemini 3.5 Flash kind of makes all that routing logic seem pointless. It’s the core engine we’ve needed to build apps that are both smart and snappy. You don’t have to choose between speed and brains anymore. You can build the heavy feature and watch it load right away. That’s what Gemini 3.5 Flash actually delivers.
Want to go deeper?
- Check out the official Gemini API pricing details.
- Read the full Google Gemini 3.5 announcement.
- Explore more data on Artificial Analysis.